Как запустить код в пространстве ядра? eBPF!

Содержание
Обзор #
Что такое eBPF? #
eBPF (Extended Berkeley Packet Filter) — это мощная современная технология, позволяющая выполнять пользовательские программы в защищённой среде прямо в ядре Linux, не изменяя исходный код ядра и не загружая модули ядра. Изначально eBPF был создан для фильтрации сетевых пакетов, но со временем превратился в универсальный механизм для выполнения байт-кода в контексте ядра. Этот байт-код генерируется из языков высокого уровня, таких как C, Go и Rust, и загружается в ядро, где проходит проверку на безопасность и эффективность перед исполнением.
Программы eBPF работают в ограниченной среде, где прямой доступ к памяти ядра запрещён, и они могут использовать только определённые вспомогательные функции для взаимодействия с компонентами ядра и пользовательского пространства. Такой подход позволяет eBPF контролировать, отслеживать и защищать системные процессы, связанные с сетями, безопасностью и профилированием производительности, с минимальными затратами ресурсов. Возможность привязывать eBPF-программы к различным хукам ядра (например, системным вызовам, сетевым событиям или точкам трассировки) делает его чрезвычайно гибким и мощным инструментом.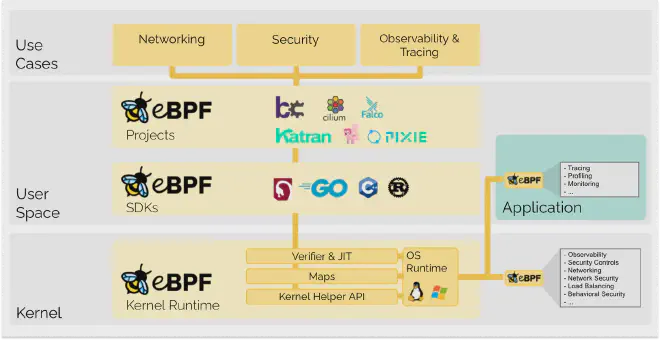
Зачем был создан eBPF? #
eBPF был создан для решения ограничений и недостатков традиционных методов настройки ядра и фильтрации сетевых пакетов. Раньше для изменения поведения ядра требовалось либо модифицировать код ядра (что рискованно и требует перезагрузки системы), либо загружать модули ядра, которые могли создавать уязвимости и приводить к нестабильности системы.
eBPF стал решением для безопасного, динамического и реального исполнения кода в ядре. Он позволяет разработчикам расширять функционал ядра без ущерба для безопасности и производительности. Кроме того, eBPF открыл новые возможности для трассировки, наблюдаемости и мониторинга на уровне системы, избегая при этом риска сбоев или нестабильности системы.
Безопасность #
Безопасность — один из важнейших аспектов eBPF. Каждая программа eBPF проверяется ядром с помощью специального проверяющего (верификатора), чтобы убедиться, что она не обращается к несанкционированной памяти и не выполняет вредоносных действий. Эта среда с песочницей и процесс верификации предотвращают возникновение уязвимостей и сбоев при выполнении кода на уровне ядра. Программы eBPF сильно ограничены в своих действиях и могут полагаться только на предопределённые вспомогательные функции и контролируемый доступ к структурам ядра.
Глубокое понимание #
Основные компоненты #
Виртуальная машина eBPF #
Виртуальная машина eBPF — это лёгкая виртуальная машина на основе регистров, встроенная в ядро, которая позволяет запускать программы eBPF в пространстве ядра. Виртуальная машина имеет собственный набор регистров, стек и набор инструкций, поддерживая основные арифметические и логические операции, условные переходы и доступ к памяти. Так как виртуальная машина eBPF работает в пространстве ядра, она может отслеживать системные события в реальном времени, сокращая оверхед за счёт избегания частых переключений контекста между режимами ядра и пользователя.
Хуки eBPF #
eBPF работает на основе событий, что означает, что программы eBPF привязываются к определённым участкам кода в ядре, называемым хуками. Эти хуки позволяют программам eBPF отслеживать или изменять поведение ядра в ключевых точках. Существуют различные типы хуков eBPF:
kprobe: отслеживает вызовы и завершение функций ядра.cgroup: реализует контроль ресурсов и сетевые политики на основе cgroups.uprobe: отслеживает вызовы и завершение функций в пользовательском пространстве.perf events: отслеживает аппаратные счётчики производительности и программные события.tracepoints: отслеживает предопределённые статические точки трассировки в ядре.socket filters: реализует фильтрацию и анализ сетевых пакетов на уровне сокетов.XDP(eXpress Data Path): обеспечивает высокопроизводительную обработку пакетов на самом низком уровне сетевого стека Linux.
Комбинируя различные типы хуков, пользователи могут реализовывать такие функции, как мониторинг производительности, реализация сетевых политик безопасности и отладка.
Карты eBPF (eBPF Maps) #
Карты eBPF — это механизм обмена данными между пространством ядра и пользовательским пространством. Они позволяют программам eBPF хранить и извлекать данные в памяти ядра, которые затем могут быть доступны и изменены пользовательскими приложениями. Карты eBPF поддерживают различные структуры данных, включая хеш-таблицы, массивы и очереди, что делает их универсальными для различных задач.
Верификатор eBPF #
Прежде чем программа eBPF будет загружена в ядро, она проходит строгую проверку, чтобы убедиться, что она не создаёт уязвимости или нестабильность. Только проверенные программы eBPF могут быть загружены и выполнены в виртуальной машине eBPF.
- Проверка синтаксиса: проверяет, соответствует ли байт-код eBPF спецификации набора инструкций.
- Проверка потока управления: проверяет, не содержит ли программа бесконечных циклов или недопустимых переходов.
- Проверка доступа к памяти: проверяет, не обращается ли программа к несанкционированной памяти.
- Проверка вызовов вспомогательных функций: проверяет, что программа вызывает только разрешённые функции ядра.
Вспомогательные функции eBPF #
Вспомогательные функции eBPF — это набор API ядра, который позволяет программам eBPF выполнять определённые задачи, такие как взаимодействие с компонентами ядра или доступ к данным. Эти функции поддерживают различные операции, включая:
- Доступ и обновление карт eBPF.
- Получение текущего времени и даты.
- Генерацию случайных чисел.
- Получение информации о процессе или cgroup.
- Изменение сетевых пакетов или управление логикой маршрутизации.
Вспомогательные функции позволяют программам eBPF выполнять сложные операции эффективно и гибко, улучшая производительность, безопасность и мониторинг системы.
Рабочий процесс #
- Написание и компиляция программы eBPF на языках высокого уровня (обычно на C).
- Загрузка программы eBPF: программа компилируется в байт-код и загружается в ядро через системный вызов
bpf(). - Исполнение программы eBPF: программа запускается при наступлении указанного события и обрабатывает данные в реальном времени.
- Потребление данных: пользовательские приложения считывают обработанные данные из
карт eBPFилиperf events.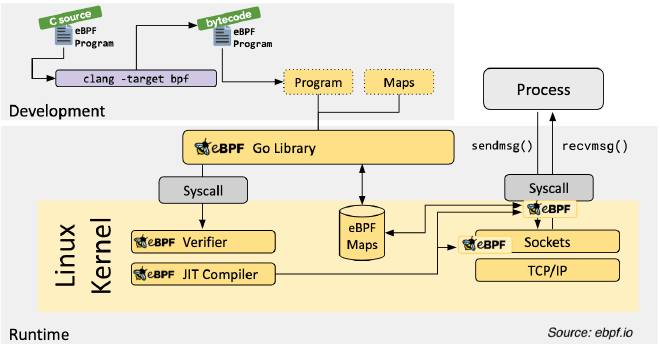

Подробные шаги #
- Программа eBPF компилируется в байт-код с использованием LLVM/Clang.
- Байт-код передаётся в ядро через системный вызов
bpf(). - Верификатор проверяет байт-код на безопасность и соответствие требованиям.
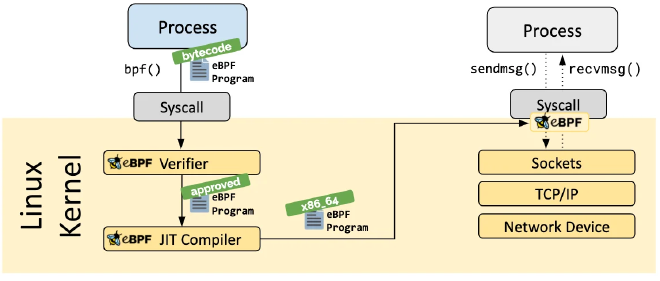
- После успешной верификации байт-код загружается в соответствующий хук ядра для исполнения. Через вспомогательные функции и хуки eBPF может взаимодействовать с компонентами ядра и пользовательским пространством. Тип программы может включать один или несколько из kprobes, uprobes, tracepoints или perf_events:
kprobes: Позволяет выполнять динамическую трассировку в ядре. Может отслеживать точки входа или выхода функций в ядре Linux, но не гарантирует стабильности между версиями ядра.uprobes: Выполняет динамическую трассировку на уровне пользователя, аналогичноkprobes, но для функций в пользовательских программах.tracepoints: Обеспечивает статическую трассировку внутри ядра. Это предопределённые точки, поддерживаемые разработчиками ядра, которые предлагают стабильный интерфейс ABI.perf_events: Обеспечивает выборку счётчиков производительности оборудования и PMC (счётчиков мониторинга производительности).
- Программы eBPF работают в двух пространствах: пользовательском и ядра. Существует два основных способа взаимодействия между ними:
Карты BPF: используются для статистики и агрегации данных.perf events: используются для мониторинга и трассировки данных в реальном времени.

Таким образом, eBPF позволяет внедрять пользовательский код в ядро без необходимости обновления ядра. Он предоставляет возможность мониторить и собирать данные о выполнении определённых путей как в ядре, так и в пользовательском пространстве. Программы eBPF временно сохраняют данные в картах BPF, которые затем могут быть считаны пользовательскими приложениями для анализа или сохранения.
Написание программы eBPF #
Напишем программу eBPF, которая будет использовать технологию eXpress Data Path (XDP) для захвата сетевых пакетов на самом низком уровне сетевого стека ядра Linux, что позволит эффективно инспектировать и анализировать пакеты по мере их поступления в систему. Программа будет фокусироваться на извлечении ключевой информации, такой как IP-адреса источника и назначения, порты, протоколы и размер пакета для TCP и UDP пакетов, которые затем отправятся в пользовательское пространство через кольцевой буфер для дальнейшего анализа.
Давайте разберем код на ключевые разделы и подробно рассмотрим каждый из них.
Код в пространстве ядра (Kernel-space) #
Начальная настройка #
//go:build ignore
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
#include <linux/if_ether.h>
#include <linux/ip.h>
#include <linux/tcp.h>
#include <linux/udp.h>
#include <linux/in.h>
//go:build ignore: Эта директива гарантирует, что код будет проигнорирован системой сборки Go, так как это не типичный код на Go, а программа eBPF, написанная на C, которая будет отдельно скомпилирована с использованием инструментов eBPF.<linux/bpf.h>: Содержит основные структуры данных и макросы, используемые в программах eBPF, включаяXDP-хукииBPF-хелперы.<bpf/bpf_helpers.h>: Предоставляет вспомогательные функции для взаимодействия с ядром (например, для работы с картами или выполнения операций с памятью).<linux/if_ether.h>: Определяет структуры заголовков Ethernet и константы для анализа кадров Ethernet.<linux/ip.h>: Определяет структуры заголовков IP и константы, используемые для интерпретации IP-пакетов.<linux/tcp.h>и<linux/udp.h>: Содержат определения структур заголовков TCP и UDP, что позволяет извлекать порты источника и назначения.<linux/in.h>: Предоставляет константы для протоколов, таких какIPPROTO_TCPиIPPROTO_UDP, используемые для различения пакетов TCP и UDP.
Определение структуры данных для информации о пакетах #
// Data structure to send packet details to user space via ring buffer
struct packet_data {
__u32 src_ip;
__u32 dst_ip;
__u16 src_port;
__u16 dst_port;
__u32 protocol;
__u32 packet_size;
};
Эта структура, packet_data, хранит информацию о захваченных сетевых пакетах. Она будет отправлена в пользовательское пространство для дальнейшего анализа.
src_ipиdst_ip: Сохраняют IP-адреса источника и назначения.src_portиdst_port: Фиксируют порты источника и назначения (используются для TCP и UDP пакетов).protocol: Содержит протокол пакета, например TCP или UDP.packet_size: Хранит общий размер пакета в байтах.
Определение карты кольцевого буфера #
// Define a ring buffer map to send packet data to user space
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 1 << 24); // 16 MB ring buffer
} packet_ringbuf SEC(".maps");
- Этот блок определяет карту eBPF типа
BPF_MAP_TYPE_RINGBUF. Карта действует как кольцевой буфер, позволяющий ядру отправлять данные пакетов в пользовательское пространство. max_entriesзадает размер кольцевого буфера, в данном случае это 1 « 24 (16 МБ). Этого должно быть достаточно для хранения данных о захваченных пакетах.
Директива SEC(".maps") помечает эту структуру как часть секции карт, что требуется для карт eBPF.
Точка входа программы XDP: capture_packet_data #
SEC("xdp")
int capture_packet_data(struct xdp_md *ctx) {
void *data_end = (void *)(long)ctx->data_end;
void *data = (void *)(long)ctx->data;
- Программа XDP: Это отмечает функцию как хук XDP (eXpress Data Path), что позволяет программе обрабатывать пакеты на самом низком уровне, как только они поступают на сетевой интерфейс.
- Функция принимает один аргумент
ctx, который является указателем на структуруxdp_md, содержащую метаданные о пакете. - data и data_end: Эти указатели определяют границы данных пакета. Мы будем использовать их, чтобы убедиться, что не обращаемся к памяти за пределами размера пакета, что предотвратит ошибки работы с памятью.
Разбор заголовка Ethernet #
struct ethhdr *eth = data;
if ((void *)(eth + 1) > data_end) {
return XDP_PASS; // Packet is too small to be valid
}
- Первый шаг — это разбор заголовка Ethernet (
ethhdr) из пакета. - Программа проверяет, достаточно ли велик пакет для того, чтобы содержать полный заголовок Ethernet, проверяя, что доступ к данным заголовка не превышает границ
data_end. - Если пакет слишком мал, программа завершает работу, возвращая
XDP_PASS, что означает, что пакет продолжит обработку в обычном сетевом стеке.
Проверка, является ли пакет IP-пакетом #
if (eth->h_proto != __constant_htons(ETH_P_IP)) {
return XDP_PASS; // Not an IP packet
}
- Здесь мы проверяем, является ли пакет IP-пакетом, проверяя, совпадает ли поле EtherType (
h_proto) в заголовке Ethernet со значениемETH_P_IP(значение для IPv4). - Если пакет не является IP-пакетом, мы возвращаем
XDP_PASS, чтобы позволить нормальную обработку.
Парсинг IP-заголовка и извлечение IP-информации #
struct iphdr *ip = data + sizeof(struct ethhdr);
if ((void *)(ip + 1) > data_end) {
return XDP_PASS; // IP header is incomplete
}
struct packet_data pkt_data = {};
pkt_data.src_ip = __builtin_bswap32(ip->saddr); // Convert source IP to host byte order
pkt_data.dst_ip = __builtin_bswap32(ip->daddr); // Convert destination IP to host byte order
pkt_data.protocol = ip->protocol;
// Calculate total packet size
pkt_data.packet_size = (__u32)(data_end - data);
- Мы перемещаемся за заголовок Ethernet, чтобы получить доступ к IP-заголовку (
iphdr). - Аналогично заголовку Ethernet, мы проверяем, полностью ли IP-заголовок находится в пределах пакета. Если нет, программа завершает работу.
- IP-адреса источника и назначения сохраняются в структуре
pkt_dataпосле их преобразования в порядок байт хоста с использованием функции__builtin_bswap32(так как IP-адреса хранятся в сетевом порядке байт). - Поле протокола (например, TCP, UDP) также сохраняется.
- Наконец, мы вычисляем общий размер пакета, вычитая начало пакета (data) из конца пакета (
data_end).
Обработка TCP и UDP пакетов #
if (ip->protocol == IPPROTO_TCP) {
struct tcphdr *tcp = data + sizeof(struct ethhdr) + sizeof(struct iphdr);
if ((void *)(tcp + 1) > data_end) {
return XDP_PASS; // TCP header is incomplete
}
pkt_data.src_port = __builtin_bswap16(tcp->source);
pkt_data.dst_port = __builtin_bswap16(tcp->dest);
} else if (ip->protocol == IPPROTO_UDP) {
struct udphdr *udp = data + sizeof(struct ethhdr) + sizeof(struct iphdr);
if ((void *)(udp + 1) > data_end) {
return XDP_PASS; // UDP header is incomplete
}
pkt_data.src_port = __builtin_bswap16(udp->source);
pkt_data.dst_port = __builtin_bswap16(udp->dest);
}
- Если пакет является TCP или UDP, мы далее разбираем заголовки транспортного уровня.
- TCP: Программа проверяет, полностью ли содержится заголовок TCP в пакете, затем извлекает и преобразует порты источника и назначения в порядок байт хоста с использованием функции
__builtin_bswap16. - UDP: Аналогично, мы проверяем заголовок UDP и извлекаем порты источника и назначения.
Отправка данных пакета в пользовательское пространство через кольцевой буфер #
void *ringbuf_data = bpf_ringbuf_reserve(&packet_ringbuf, sizeof(pkt_data), 0);
if (!ringbuf_data) {
return XDP_PASS; // Failed to reserve space in ring buffer
}
__builtin_memcpy(ringbuf_data, &pkt_data, sizeof(pkt_data));
bpf_ringbuf_submit(ringbuf_data, 0);
- Функция пытается зарезервировать место в кольцевом буфере с помощью
bpf_ringbuf_reserve. Если зарезервировать место не удалось, программа завершает работу. - Если резервирование успешно, мы копируем структуру
pkt_dataв кольцевой буфер с использованием функции__builtin_memcpy, а затем отправляем данные с помощьюbpf_ringbuf_submit.
Декларация лицензии программы #
char __license[] SEC("license") = "Dual MIT/GPL";
- Эта строка указывает лицензию программы eBPF, позволяя использовать ее под лицензиями MIT и GPL. Это требуется ядром для загрузки программы eBPF.
Полный код #
Как видите, код eBPF очень похож на C. На самом деле программы eBPF пишутся на ограниченном подмножестве C.
Кликни сюда, чтобы увидеть весь код:
// packet_sniff.c
//go:build ignore
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
#include <linux/if_ether.h>
#include <linux/ip.h>
#include <linux/tcp.h>
#include <linux/udp.h>
#include <linux/in.h>
// Data structure to send packet details to user space via ring buffer
struct packet_data {
__u32 src_ip;
__u32 dst_ip;
__u16 src_port;
__u16 dst_port;
__u32 protocol;
__u32 packet_size;
};
// Define a ring buffer map to send packet data to user space
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 1 << 24); // 16 MB ring buffer
} packet_ringbuf SEC(".maps");
// XDP program to capture packet data
SEC("xdp")
int capture_packet_data(struct xdp_md *ctx) {
void *data_end = (void *)(long)ctx->data_end;
void *data = (void *)(long)ctx->data;
// Parse Ethernet header
struct ethhdr *eth = data;
if ((void *)(eth + 1) > data_end) {
return XDP_PASS; // Packet is too small to be valid
}
// Check if the packet is an IP packet
if (eth->h_proto != __constant_htons(ETH_P_IP)) {
return XDP_PASS; // Not an IP packet
}
// Parse IP header
struct iphdr *ip = data + sizeof(struct ethhdr);
if ((void *)(ip + 1) > data_end) {
return XDP_PASS; // IP header is incomplete
}
// Initialize packet_data structure to store details
struct packet_data pkt_data = {};
pkt_data.src_ip = __builtin_bswap32(ip->saddr); // Convert source IP to host byte order
pkt_data.dst_ip = __builtin_bswap32(ip->daddr); // Convert destination IP to host byte order
pkt_data.protocol = ip->protocol;
// Calculate total packet size
pkt_data.packet_size = (__u32)(data_end - data);
// Handle TCP or UDP packet to extract source and destination ports
if (ip->protocol == IPPROTO_TCP) {
struct tcphdr *tcp = data + sizeof(struct ethhdr) + sizeof(struct iphdr);
if ((void *)(tcp + 1) > data_end) {
return XDP_PASS; // TCP header is incomplete
}
pkt_data.src_port = __builtin_bswap16(tcp->source); // Convert source port to host byte order
pkt_data.dst_port = __builtin_bswap16(tcp->dest); // Convert destination port to host byte order
} else if (ip->protocol == IPPROTO_UDP) {
struct udphdr *udp = data + sizeof(struct ethhdr) + sizeof(struct iphdr);
if ((void *)(udp + 1) > data_end) {
return XDP_PASS; // UDP header is incomplete
}
pkt_data.src_port = __builtin_bswap16(udp->source); // Convert source port to host byte order
pkt_data.dst_port = __builtin_bswap16(udp->dest); // Convert destination port to host byte order
}
// Send the captured packet data to user space via ring buffer
void *ringbuf_data = bpf_ringbuf_reserve(&packet_ringbuf, sizeof(pkt_data), 0);
if (!ringbuf_data) {
return XDP_PASS; // Failed to reserve space in ring buffer
}
// Copy packet data into the ring buffer and submit it
__builtin_memcpy(ringbuf_data, &pkt_data, sizeof(pkt_data));
bpf_ringbuf_submit(ringbuf_data, 0);
return XDP_PASS; // Continue processing packet as normal
}
// eBPF program license
char __license[] SEC("license") = "Dual MIT/GPL";
Код в пользовательском пространстве (User-space) #
Далее напишем Go-код, который интегрирует программу eBPF (Extended Berkeley Packet Filter) с пользовательским приложением для захвата и анализа данных сетевых пакетов в реальном времени. Он делает это, прикрепляя программу XDP (eXpress Data Path) к указанному сетевому интерфейсу, используя пакет github.com/cilium/ebpf для управления объектами eBPF и получения данных о пакетах через кольцевой буфер.
Импорты, карта протоколов (Maps), структура для захваченных данных пакета #
import (
"bytes"
"encoding/binary"
"flag"
"fmt"
"log"
"net"
"os"
"os/signal"
"syscall"
"github.com/cilium/ebpf/link"
"github.com/cilium/ebpf/ringbuf"
"github.com/cilium/ebpf/rlimit"
)
github.com/cilium/ebpf/*:link: Для прикрепления eBPF-программ к сетевым интерфейсам.ringbuf: Для чтения событий из кольцевого буфера eBPF.rlimit: Для управления ограничениями ресурсов, такими как блокировка памяти для программ eBPF.
var protocolMap = map[int]string{
1: "ICMP",
2: "IGMP",
6: "TCP",
17: "UDP",
41: "IPv6",
89: "OSPF",
132: "SCTP",
255: "Reserved",
}
protocolMap— это карта, сопоставляющая номера протоколов с их понятными человеку названиями. Например, номер протокола6соответствует “TCP”, а17— “UDP”. Эта карта используется для отображения протокола в читаемом формате при захвате данных пакетов.
type packetData struct {
SrcIP uint32
DstIP uint32
SrcPort uint16
DstPort uint16
Protocol uint32
PacketSize uint32
}
packetDataотображает структуруpacket_data, определённую в программе eBPF на C. Она содержит информацию о пакете.
Функция main #
func main() {
// Parse the network interface name from the command line
ifaceName := flag.String("iface", "lo", "Network interface to monitor")
flag.Parse()
// Remove memory lock limit for eBPF
if err := rlimit.RemoveMemlock(); err != nil {
log.Fatalf("Failed to remove memlock: %v", err)
}
- Снятие блокировки памяти: Так как программы eBPF требуют блокировки определённого объёма памяти,
rlimit.RemoveMemlock()снимает любые ограничения на блокировку памяти, обеспечивая возможность правильной работы программы eBPF.
Загрузка объектов eBPF #
// Load compiled eBPF objects from ELF
var objs packetSniffObjects
if err := loadPacketSniffObjects(&objs, nil); err != nil {
log.Fatalf("Error loading eBPF objects: %v", err)
}
defer objs.Close()
packetSniffObjects: Эта переменная содержит скомпилированные объекты eBPF из файлаpacket_sniff.c. Они создаются с использованием инструментаbpf2go, который компилирует C-код eBPF в пакет Go.loadPacketSniffObjects: Эта функция загружает объекты eBPF в ядро. Если во время загрузки возникает ошибка, программа регистрирует ошибку и завершает работу.
Прикрепление программы XDP #
// Get network interface by name
iface, err := net.InterfaceByName(*ifaceName)
if err != nil {
log.Fatalf("Error getting interface %s: %v", *ifaceName, err)
}
// Attach the eBPF XDP program to the specified network interface
xdpLink, err := link.AttachXDP(link.XDPOptions{
Program: objs.CapturePacketData,
Interface: iface.Index,
})
if err != nil {
log.Fatalf("Error attaching XDP program: %v", err)
}
defer xdpLink.Close()
net.InterfaceByName: Извлекает сетевой интерфейс по его имени. Например, если указатьeth0, она вернёт сетевой интерфейсeth0.- Прикрепление XDP: Программа eBPF прикрепляется к сетевому интерфейсу с использованием
link.AttachXDP. Теперь программа будет отслеживать пакеты на этом интерфейсе на уровне XDP, который работает на уровне сетевого устройства.
Настройка кольцевого буфера для сбора данных #
// Create a ring buffer reader to receive events from the eBPF program
rd, err := ringbuf.NewReader(objs.PacketRingbuf)
if err != nil {
log.Fatalf("Error creating ring buffer reader: %v", err)
}
defer rd.Close()
log.Printf("Monitoring packets on interface: %s", *ifaceName)
ringbuf.NewReader: Эта функция создаёт читателя для кольцевого буфера, который используется программой eBPF для отправки данных пакетов в пользовательское пространство. Этот читатель непрерывно читает новые события (данные пакетов) из кольцевого буфера eBPF.- Программа выводит сообщение, указывающее, что она начала мониторинг пакетов на указанном интерфейсе.
Обработка корректного завершения работы #
// Set up signal handling for graceful exit
stopChan := make(chan os.Signal, 1)
signal.Notify(stopChan, os.Interrupt, syscall.SIGTERM)
- Обработка сигналов: Этот раздел настраивает слушатель для перехвата сигналов прерывания (например,
Ctrl+C). Если программа получает сигнал прерывания или завершения, она может корректно завершить работу, очистив ресурсы.
Основной цикл мониторинга пакетов #
for {
select {
case <-stopChan:
log.Println("Received interrupt, exiting...")
return
default:
// Read packet data from the ring buffer
record, err := rd.Read()
if err != nil {
log.Fatalf("Error reading from ring buffer: %v", err)
}
// Parse the raw packet data
var pkt packetData
err = binary.Read(bytes.NewReader(record.RawSample), binary.LittleEndian, &pkt)
if err != nil {
log.Fatalf("Error parsing packet data: %v", err)
}
- Основной цикл: Это основной цикл, в котором программа непрерывно читает новые данные о пакетах из кольцевого буфера.
rd.Read(): Читает новую запись (захваченный пакет) из кольцевого буфера.- Разбор данных пакета: Сырые данные из кольцевого буфера интерпретируются в структуру packetData с помощью binary.Read, интерпретируя данные в формате Little-endian.
Вывод информации о пакетах #
// Convert IP addresses to human-readable format and print details
srcIP := intToIP(pkt.SrcIP)
dstIP := intToIP(pkt.DstIP)
protocolName := "Unknown"
if name, exists := protocolMap[int(pkt.Protocol)]; exists {
protocolName = name
}
fmt.Printf("Protocol: %s, Src: %s:%d, Dst: %s:%d, Size: %d bytes\n",
protocolName, srcIP, pkt.SrcPort, dstIP, pkt.DstPort, pkt.PacketSize)
}
}
}
- Преобразование IP-адресов: IP-адреса источника и назначения, которые хранятся как значения
uint32, преобразуются в понятные человеку IP-адреса с использованием вспомогательной функцииintToIP. - Поиск протокола: Номер протокола сопоставляется с именем протокола (например, TCP или UDP) с использованием
protocolMap. Если протокол не распознан, по умолчанию выводится “Unknown”. - Вывод деталей пакета: Программа выводит информацию о протоколе, IP-адресах источника и назначения, портах и размере пакета в читаемом формате.
Вспомогательная функция: intToIP #
func intToIP(ip uint32) string {
ipBytes := make([]byte, 4)
binary.BigEndian.PutUint32(ipBytes, ip)
return net.IP(ipBytes).String()
}
intToIPпреобразует 32-битное целое число (IPv4-адрес) в строковый формат (x.x.x.x). Она преобразует целое число в байтовый срез с использованиемbinary.BigEndian, что необходимо, так как IP-адреса обычно хранятся в формате big-endian.
Полный код #
Кликни сюда, чтобы увидеть весь код:
// main.go
package main
//go:generate go run github.com/cilium/ebpf/cmd/bpf2go packetSniff packet_sniff.c
import (
"bytes"
"encoding/binary"
"flag"
"fmt"
"log"
"net"
"os"
"os/signal"
"syscall"
"github.com/cilium/ebpf/link"
"github.com/cilium/ebpf/ringbuf"
"github.com/cilium/ebpf/rlimit"
)
var (
// Map protocol number to a human-readable protocol name
protocolMap = map[int]string{
1: "ICMP",
2: "IGMP",
6: "TCP",
17: "UDP",
41: "IPv6",
89: "OSPF",
132: "SCTP",
255: "Reserved",
}
)
// Struct that mirrors the packet_data structure in the eBPF program
type packetData struct {
SrcIP uint32
DstIP uint32
SrcPort uint16
DstPort uint16
Protocol uint32
PacketSize uint32
}
func main() {
// Parse the network interface name from the command line
ifaceName := flag.String("iface", "lo", "Network interface to monitor")
flag.Parse()
// Remove memory lock limit for eBPF
if err := rlimit.RemoveMemlock(); err != nil {
log.Fatalf("Failed to remove memlock: %v", err)
}
// Load compiled eBPF objects from ELF
var objs packetSniffObjects
if err := loadPacketSniffObjects(&objs, nil); err != nil {
log.Fatalf("Error loading eBPF objects: %v", err)
}
defer objs.Close()
// Get network interface by name
iface, err := net.InterfaceByName(*ifaceName)
if err != nil {
log.Fatalf("Error getting interface %s: %v", *ifaceName, err)
}
// Attach the eBPF XDP program to the specified network interface
xdpLink, err := link.AttachXDP(link.XDPOptions{
Program: objs.CapturePacketData,
Interface: iface.Index,
})
if err != nil {
log.Fatalf("Error attaching XDP program: %v", err)
}
defer xdpLink.Close()
// Create a ring buffer reader to receive events from the eBPF program
rd, err := ringbuf.NewReader(objs.PacketRingbuf)
if err != nil {
log.Fatalf("Error creating ring buffer reader: %v", err)
}
defer rd.Close()
log.Printf("Monitoring packets on interface: %s", *ifaceName)
// Set up signal handling for graceful exit
stopChan := make(chan os.Signal, 1)
signal.Notify(stopChan, os.Interrupt, syscall.SIGTERM)
// Main event loop
for {
select {
case <-stopChan:
log.Println("Received interrupt, exiting...")
return
default:
// Read packet data from the ring buffer
record, err := rd.Read()
if err != nil {
log.Fatalf("Error reading from ring buffer: %v", err)
}
// Parse the raw packet data
var pkt packetData
err = binary.Read(bytes.NewReader(record.RawSample), binary.LittleEndian, &pkt)
if err != nil {
log.Fatalf("Error parsing packet data: %v", err)
}
// Convert IP addresses to human-readable format and print details
srcIP := intToIP(pkt.SrcIP)
dstIP := intToIP(pkt.DstIP)
protocolName := "Unknown"
if name, exists := protocolMap[int(pkt.Protocol)]; exists {
protocolName = name
}
fmt.Printf("Protocol: %s, Src: %s:%d, Dst: %s:%d, Size: %d bytes\n",
protocolName, srcIP, pkt.SrcPort, dstIP, pkt.DstPort, pkt.PacketSize)
}
}
}
// Convert a uint32 IP address to a readable string
func intToIP(ip uint32) string {
ipBytes := make([]byte, 4)
binary.BigEndian.PutUint32(ipBytes, ip)
return net.IP(ipBytes).String()
}
Генерируем, билдим и запускаем #
Теперь мы можем сгенерировать код eBPF и компилировать приложение.

Запуск приложения
Где можно еще использовать eBPF? #
Гибкость eBPF делает его идеальным для широкого круга реальных приложений в безопасности, мониторинге и других областях. Основные случаи применения:
- Обеспечение безопасности
eBPF может создавать передовые механизмы безопасности, такие как обнаружение вторжений и защита во время выполнения. Он может отслеживать и блокировать подозрительное поведение (например, несанкционированный доступ к файлам), обнаруживать DDoS-атаки и обеспечивать безопасность контейнерных сред, отслеживая системные вызовы.Крупные компании, такие как Netflix, используют eBPF для блокировки вредоносного трафика во время DDoS-атак в реальном времени, фильтруя вредоносные пакеты на сетевом уровне с минимальными затратами ресурсов. - Трассировка и отладка
eBPF поддерживает динамическую трассировку и инструменты отладки, такие как bcc и BPFtrace, что позволяет проводить анализ производительности в реальном времени (например, использование памяти и процессорного времени) без необходимости модифицировать код приложения. - Балансировка нагрузки
eBPF помогает строить эффективные балансировщики нагрузки прямо в ядре Linux, распределяя сетевой трафик между серверами, сокращая задержки и улучшая время отклика с минимальной нагрузкой на ресурсы. - Наблюдаемость и сбор метрик
Такие инструменты, как Prometheus и Grafana, используют eBPF для сбора системных метрик, отслеживания поведения контейнеров и предоставления детализированной информации о производительности системы без её замедления.