How to run code in kernel space? eBPF!

Table of Contents
Overview #
What is eBPF? #
eBPF, or Extended Berkeley Packet Filter, is a powerful, modern technology that allows users to execute custom sandboxed programs directly within the Linux kernel without modifying the kernel source or loading kernel modules. Originally designed for packet filtering (hence the name), eBPF has evolved into a general-purpose engine capable of executing bytecode in the kernel context. This bytecode is generated from high-level languages such as C, Go, and Rust, and is loaded and verified by the kernel to ensure it is safe and efficient before execution.
eBPF programs run in a restricted environment where direct access to kernel memory is prohibited, and they can only use specific helper functions to interact with kernel and user-space components. This design allows eBPF to monitor, trace, and protect system activities such as networking, security, and performance profiling with minimal overhead. Its ability to attach to various kernel hooks (such as system calls, network events, or tracepoints) makes it highly versatile and powerful.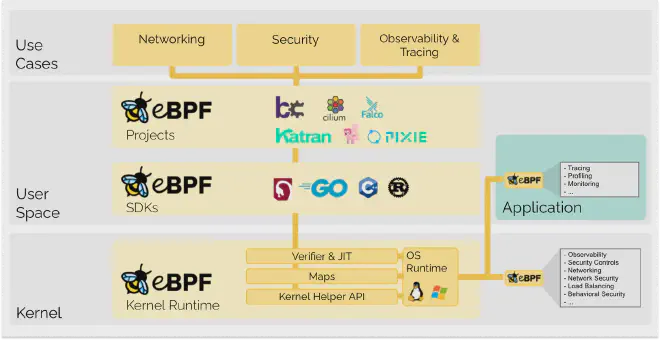
Why Was it Invented? #
eBPF was invented to address the limitations and inefficiencies of traditional kernel tuning and network packet filtering methods. Before eBPF, changing kernel behavior required either modifying kernel code which was risky and required reboots or loading kernel modules, which could introduce security vulnerabilities or instability.
To solve these problems, eBPF was introduced as a solution for safe, dynamic, and real-time code execution in the kernel. It allows developers to extend kernel functionality without compromising safety or performance. Additionally, it has unlocked new possibilities for tracing, observability, and system-level monitoring, all while avoiding the risks of kernel crashes or system instability.
Its Security #
Security is one of eBPF’s most crucial aspects. Every eBPF program is verified by the kernel’s eBPF verifier before execution, ensuring that it does not access unauthorized memory or engage in harmful behaviors. This sandboxing and verification process prevents security vulnerabilities and crashes that might otherwise occur with kernel-level code execution. Additionally, eBPF programs are highly restricted in what they can do, relying on predefined helper functions and controlled access to kernel structures.
Deeper understanding #
Core Components #
eBPF Virtual machine #
The eBPF VM is a lightweight, register-based virtual machine embedded in the kernel that allows eBPF programs to run in kernel space. The eBPF VM has its own independent register set, stack space, and instruction set, supporting basic arithmetic, logical operations, conditional jumps, and memory access. Since the eBPF VM operates in kernel space, it can monitor system events in real time, reducing performance overhead by avoiding frequent context switches between user and kernel modes.
eBPF Hooks #
eBPF is event-driven, meaning that eBPF programs are attached to specific code paths in the kernel, known as “hooks.” These hooks allow eBPF programs to observe or manipulate kernel behavior at key points. There are several types of hooks that eBPF provides:
kprobe(Kernel probe): Monitors kernel function call and return events (executed before or after a specified kernel function).cgroup: Implements resource control and network policies based on cgroups (control groups).uprobes: Monitors the call and return events of user-space functions.perf events: Monitors hardware performance counters and software-defined performance events.tracepoints: Monitors predefined static tracepoints in the kernel.socket filters: Implements socket-level packet filtering and analysis.XDP(eXpress Data Path): Provides high-performance packet processing and filtering at the lowest level in the Linux network stack.
By combining different types of eBPF hooks, users can implement various functions, such as performance monitoring, network security policy enforcement, and debugging.
eBPF Maps #
eBPF Maps are a mechanism for exchanging data between kernel space and user space. They allow eBPF programs to store and retrieve data in kernel memory, which can then be accessed and modified by user-space applications. eBPF Maps support various data structures, including hash tables, arrays, and queues, meeting the needs of different use cases.
eBPF Verifier #
Before being loaded into the kernel, an eBPF program undergoes rigorous verification to ensure it does not introduce vulnerabilities or instability. Only verified eBPF programs can be loaded into the kernel and executed in the eBPF VM.
Syntax checking: Ensures that the eBPF program bytecode complies with the instruction set specification.Control flow checking: Ensures that the eBPF program does not contain infinite loops or illegal jumps.Memory access checking: Ensures that the eBPF program does not access unauthorized memory or sensitive kernel data.Helper Function Checking: Ensures that the eBPF program only calls allowed kernel helper functions.
eBPF Helpers #
eBPF helper functions are a set of kernel APIs that allow eBPF programs to perform specific tasks, such as interacting with kernel components or accessing data. These helpers support various operations, such as:
- Accessing and updating eBPF maps.
- Retrieving the current time and date.
- Generating random numbers.
- Retrieving process or cgroup context.
- Modifying network packets or managing forwarding logic.
Helper functions enable eBPF programs to perform complex operations efficiently and flexibly, enhancing system performance, security, and monitoring.
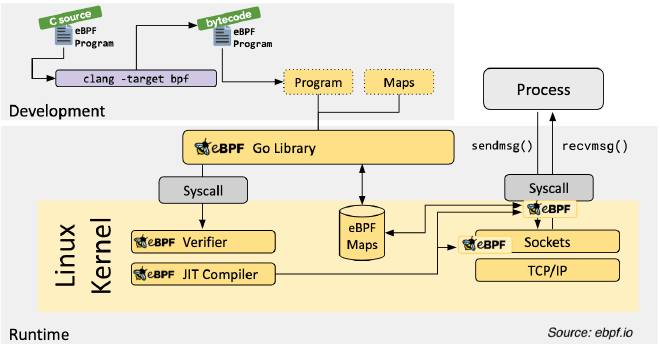
Workflow #
- Writing and compiling eBPF programs using high-level languages (usually in C).
- Loading the eBPF program: The program is compiled into bytecode and loaded into the kernel via the
bpf()system call. - Executing the eBPF program: The program is triggered when the specified event occurs, and it processes data in real time.
- Data Consumption: User-space applications read the processed data from eBPF Maps or perf events.

Detailed Steps #
- The BPF program is compiled into eBPF bytecode using LLVM/Clang.
- The bytecode is passed to the kernel via the
bpf()system call. - The verifier checks the bytecode for safety and compliance.
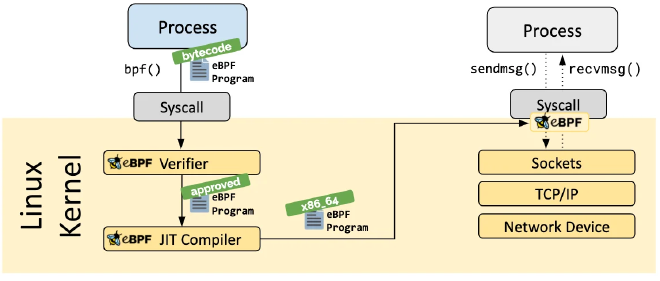
- After successful verification, the bytecode is loaded into the appropriate kernel hook for execution. Through the helper and hook mechanisms, eBPF can interact with kernel or user-space components. The program type could include one or more of
kprobes,uprobes,tracepoints, orperf_events:kprobes: Enables dynamic tracing in the kernel. It can trace function entry or return points in the Linux kernel but does not guarantee stability across kernel versions.uprobes: Performs user-level dynamic tracing, similar tokprobes, but for functions in user programs.tracepoints: Provides static tracing within the kernel. These are predefined points maintained by kernel developers, offering a stable ABI interface.perf_events: Provides hardware performance counter sampling and PMC (performance monitoring counters).
- User space communicates with the kernel through BPF Maps. BPF Maps are key-value stores that are accessed via file descriptors. They allow data sharing across multiple calls and between the kernel and user space. eBPF programs can access up to 64 Maps, and multiple eBPF programs can share the same Map.
- eBPF programs run in both user space and kernel space. There are two primary ways to interact between these spaces:
BPF map: Used for statistics and data aggregation.perf-event: Used for real-time monitoring and tracing data in user space.

To summarize, eBPF allows user code to be injected into the kernel without requiring a kernel update. It provides the ability to monitor and collect data about specific kernel or user-space execution paths. eBPF programs temporarily store output data in BPF Maps, which can be read by user-space applications for analysis or persistent storage.
Writing the eBPF Program #
We will write an eBPF program that will use eXpress Data Path (XDP) technology to capture network packets at the lowest level of the Linux kernel network stack, allowing us to efficiently inspect and analyze packets as they enter the system. The program will focus on extracting key information such as source and destination IP addresses, ports, protocols, and packet size for TCP and UDP packets, which will then be sent to user space via a ring buffer for further analysis.
Let’s break the code down into key sections and look at each one in detail.
Kernel Space Code #
Initial Setup #
//go:build ignore
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
#include <linux/if_ether.h>
#include <linux/ip.h>
#include <linux/tcp.h>
#include <linux/udp.h>
#include <linux/in.h>
//go:build ignore: This directive ensures that the code is ignored by the Go build system, as it’s not typical Go code but rather an eBPF program written in C that will be compiled separately using eBPF tooling.<linux/bpf.h>: Contains essential data structures and macros used in eBPF programs, including XDP hooks and BPF helpers.<bpf/bpf_helpers.h>: Provides helper functions for interacting with the kernel (e.g., accessing maps, performing memory operations).<linux/if_ether.h>: Defines Ethernet header structures and constants for parsing Ethernet frames.<linux/ip.h>: Defines the IP header structures and constants used to interpret IP packets.<linux/tcp.h>and<linux/udp.h>: Contain the structure definitions for TCP and UDP headers, allowing us to extract source and destination ports.<linux/in.h>: Provides constants for protocols such as IPPROTO_TCP and IPPROTO_UDP, used to differentiate between TCP and UDP packets.
Defining Data Structure for Packet Information #
// Data structure to send packet details to user space via ring buffer
struct packet_data {
__u32 src_ip;
__u32 dst_ip;
__u16 src_port;
__u16 dst_port;
__u32 protocol;
__u32 packet_size;
};
This structure, packet_data, holds information about the captured network packets. It will be sent to user space for further analysis.
src_ipanddst_ip: Store the source and destination IP addresses.src_portanddst_port: Capture the source and destination ports (used for TCP and UDP packets).protocol: Holds the packet’s protocol, such as TCP or UDP.packet_size: Stores the total size of the packet in bytes.
Ring Buffer Map Definition #
// Define a ring buffer map to send packet data to user space
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 1 << 24); // 16 MB ring buffer
} packet_ringbuf SEC(".maps");
- This block defines an eBPF map of type
BPF_MAP_TYPE_RINGBUF. The map acts as a ring buffer that allows the kernel to send packet data to user space. max_entriesspecifies the size of the ring buffer, which in this case is set to 1 « 24 (16 MB). This should provide ample space for storing captured packet data.
The SEC(".maps") directive marks this structure as part of the maps section, which is required for eBPF maps.
XDP Program Entry Point: capture_packet_data #
SEC("xdp")
int capture_packet_data(struct xdp_md *ctx) {
void *data_end = (void *)(long)ctx->data_end;
void *data = (void *)(long)ctx->data;
- XDP Program: This marks the function as an XDP (eXpress Data Path) hook, which allows the program to process packets at the lowest level, right when they are received by the network interface.
- The function takes a single argument,
ctx, which is a pointer to anxdp_mdstructure containing metadata about the packet. - data and data_end: These pointers define the boundaries of the packet data. We will use them to ensure we don’t access memory beyond the packet’s size, preventing memory errors.
Parsing Ethernet Header #
struct ethhdr *eth = data;
if ((void *)(eth + 1) > data_end) {
return XDP_PASS; // Packet is too small to be valid
}
- The first step is to parse the Ethernet header (
ethhdr) from the packet. - The program checks if the packet is large enough to contain a complete Ethernet header by verifying that accessing beyond the end of the Ethernet header does not exceed
data_end. - If the packet is too small, the program exits early by returning
XDP_PASS, meaning the packet will continue to the regular networking stack.
Checking if the Packet is an IP Packet #
if (eth->h_proto != __constant_htons(ETH_P_IP)) {
return XDP_PASS; // Not an IP packet
}
- Here, we verify whether the packet is an IP packet by checking if the EtherType field (
h_proto) in the Ethernet header matchesETH_P_IP(the value for IPv4). - If the packet is not an IP packet, we return
XDP_PASSto allow normal processing.
Parsing IP Header and Extracting IP Information #
struct iphdr *ip = data + sizeof(struct ethhdr);
if ((void *)(ip + 1) > data_end) {
return XDP_PASS; // IP header is incomplete
}
struct packet_data pkt_data = {};
pkt_data.src_ip = __builtin_bswap32(ip->saddr); // Convert source IP to host byte order
pkt_data.dst_ip = __builtin_bswap32(ip->daddr); // Convert destination IP to host byte order
pkt_data.protocol = ip->protocol;
// Calculate total packet size
pkt_data.packet_size = (__u32)(data_end - data);
- We move past the Ethernet header to access the IP header (
iphdr). - Similar to the Ethernet header, we check if the IP header is fully within the packet bounds. If not, we exit the program early.
- The IP source and destination addresses are stored in the
pkt_datastructure after converting them to host byte order using__builtin_bswap32(since IP addresses are stored in network byte order). - The protocol field (e.g., TCP, UDP) is also saved.
- Finally, we calculate the total packet size by subtracting the start of the packet (data) from the end of the packet (
data_end).
Handling TCP and UDP Packets #
if (ip->protocol == IPPROTO_TCP) {
struct tcphdr *tcp = data + sizeof(struct ethhdr) + sizeof(struct iphdr);
if ((void *)(tcp + 1) > data_end) {
return XDP_PASS; // TCP header is incomplete
}
pkt_data.src_port = __builtin_bswap16(tcp->source);
pkt_data.dst_port = __builtin_bswap16(tcp->dest);
} else if (ip->protocol == IPPROTO_UDP) {
struct udphdr *udp = data + sizeof(struct ethhdr) + sizeof(struct iphdr);
if ((void *)(udp + 1) > data_end) {
return XDP_PASS; // UDP header is incomplete
}
pkt_data.src_port = __builtin_bswap16(udp->source);
pkt_data.dst_port = __builtin_bswap16(udp->dest);
}
- If the packet is either TCP or UDP, we further parse the transport layer headers.
- TCP: The program checks if the TCP header is fully contained within the packet, then extracts and converts the source and destination ports to host byte order using
__builtin_bswap16. - UDP: Similarly, we check the UDP header and extract the source and destination ports.
Sending Packet Data to User Space via Ring Buffer #
void *ringbuf_data = bpf_ringbuf_reserve(&packet_ringbuf, sizeof(pkt_data), 0);
if (!ringbuf_data) {
return XDP_PASS; // Failed to reserve space in ring buffer
}
__builtin_memcpy(ringbuf_data, &pkt_data, sizeof(pkt_data));
bpf_ringbuf_submit(ringbuf_data, 0);
- The function attempts to reserve space in the ring buffer using
bpf_ringbuf_reserve. If the space reservation fails, the program returns early. - If successful, we copy the
pkt_datastructure into the ring buffer using__builtin_memcpyand then submit the data withbpf_ringbuf_submit.
Program License Declaration #
char __license[] SEC("license") = "Dual MIT/GPL";
- This line specifies the license for the eBPF program, allowing it to be used under both the MIT and GPL licenses. This is required by the kernel for loading the eBPF program.
Full code #
As you can see, the eBPF code is very similar to C. In reality, eBPF programs are written in a restricted subset of C.
Click here to see the full code:
// packet_sniff.c
//go:build ignore
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
#include <linux/if_ether.h>
#include <linux/ip.h>
#include <linux/tcp.h>
#include <linux/udp.h>
#include <linux/in.h>
// Data structure to send packet details to user space via ring buffer
struct packet_data {
__u32 src_ip;
__u32 dst_ip;
__u16 src_port;
__u16 dst_port;
__u32 protocol;
__u32 packet_size;
};
// Define a ring buffer map to send packet data to user space
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 1 << 24); // 16 MB ring buffer
} packet_ringbuf SEC(".maps");
// XDP program to capture packet data
SEC("xdp")
int capture_packet_data(struct xdp_md *ctx) {
void *data_end = (void *)(long)ctx->data_end;
void *data = (void *)(long)ctx->data;
// Parse Ethernet header
struct ethhdr *eth = data;
if ((void *)(eth + 1) > data_end) {
return XDP_PASS; // Packet is too small to be valid
}
// Check if the packet is an IP packet
if (eth->h_proto != __constant_htons(ETH_P_IP)) {
return XDP_PASS; // Not an IP packet
}
// Parse IP header
struct iphdr *ip = data + sizeof(struct ethhdr);
if ((void *)(ip + 1) > data_end) {
return XDP_PASS; // IP header is incomplete
}
// Initialize packet_data structure to store details
struct packet_data pkt_data = {};
pkt_data.src_ip = __builtin_bswap32(ip->saddr); // Convert source IP to host byte order
pkt_data.dst_ip = __builtin_bswap32(ip->daddr); // Convert destination IP to host byte order
pkt_data.protocol = ip->protocol;
// Calculate total packet size
pkt_data.packet_size = (__u32)(data_end - data);
// Handle TCP or UDP packet to extract source and destination ports
if (ip->protocol == IPPROTO_TCP) {
struct tcphdr *tcp = data + sizeof(struct ethhdr) + sizeof(struct iphdr);
if ((void *)(tcp + 1) > data_end) {
return XDP_PASS; // TCP header is incomplete
}
pkt_data.src_port = __builtin_bswap16(tcp->source); // Convert source port to host byte order
pkt_data.dst_port = __builtin_bswap16(tcp->dest); // Convert destination port to host byte order
} else if (ip->protocol == IPPROTO_UDP) {
struct udphdr *udp = data + sizeof(struct ethhdr) + sizeof(struct iphdr);
if ((void *)(udp + 1) > data_end) {
return XDP_PASS; // UDP header is incomplete
}
pkt_data.src_port = __builtin_bswap16(udp->source); // Convert source port to host byte order
pkt_data.dst_port = __builtin_bswap16(udp->dest); // Convert destination port to host byte order
}
// Send the captured packet data to user space via ring buffer
void *ringbuf_data = bpf_ringbuf_reserve(&packet_ringbuf, sizeof(pkt_data), 0);
if (!ringbuf_data) {
return XDP_PASS; // Failed to reserve space in ring buffer
}
// Copy packet data into the ring buffer and submit it
__builtin_memcpy(ringbuf_data, &pkt_data, sizeof(pkt_data));
bpf_ringbuf_submit(ringbuf_data, 0);
return XDP_PASS; // Continue processing packet as normal
}
// eBPF program license
char __license[] SEC("license") = "Dual MIT/GPL";
User Space Code #
Next, we’ll write Go code that integrates the eBPF (Extended Berkeley Packet Filter) program with a custom application to capture and analyze network packet data in real time. It does this by attaching the XDP (eXpress Data Path) program to a specified network interface, using the github.com/cilium/ebpf package to manipulate eBPF objects and retrieve packet data via a ring buffer.
Imports, Protocol Map, Struct for Captured Packet Data #
import (
"bytes"
"encoding/binary"
"flag"
"fmt"
"log"
"net"
"os"
"os/signal"
"syscall"
"github.com/cilium/ebpf/link"
"github.com/cilium/ebpf/ringbuf"
"github.com/cilium/ebpf/rlimit"
)
github.com/cilium/ebpf/*:link: For attaching eBPF programs to network interfaces.ringbuf: For reading events from an eBPF ring buffer.rlimit: For managing resource limits, such as memory locks for eBPF programs.
var protocolMap = map[int]string{
1: "ICMP",
2: "IGMP",
6: "TCP",
17: "UDP",
41: "IPv6",
89: "OSPF",
132: "SCTP",
255: "Reserved",
}
- The protocolMap is a map of protocol numbers to human-readable names. For example, protocol number
6maps to “TCP”, and17maps to “UDP”. This map is used to print the protocol in a readable format when packet data is captured.
type packetData struct {
SrcIP uint32
DstIP uint32
SrcPort uint16
DstPort uint16
Protocol uint32
PacketSize uint32
}
packetDatamirrors the packet_data struct defined in the eBPF C program. It contains information about the packet.
Main Function #
func main() {
// Parse the network interface name from the command line
ifaceName := flag.String("iface", "lo", "Network interface to monitor")
flag.Parse()
// Remove memory lock limit for eBPF
if err := rlimit.RemoveMemlock(); err != nil {
log.Fatalf("Failed to remove memlock: %v", err)
}
- Memory lock removal: Since eBPF programs require locking certain amounts of memory,
rlimit.RemoveMemlock()removes any memory locking restrictions, ensuring that the eBPF program can run properly.
Loading eBPF Objects #
// Load compiled eBPF objects from ELF
var objs packetSniffObjects
if err := loadPacketSniffObjects(&objs, nil); err != nil {
log.Fatalf("Error loading eBPF objects: %v", err)
}
defer objs.Close()
packetSniffObjects: This variable holds the compiled eBPF objects from the filepacket_sniff.c. It is generated using thebpf2gotool, which compiles eBPF C code into a Go package.loadPacketSniffObjects: This function loads the eBPF objects into the kernel. If there’s an error during loading, the program logs the error and terminates.
Attaching the XDP Program #
// Get network interface by name
iface, err := net.InterfaceByName(*ifaceName)
if err != nil {
log.Fatalf("Error getting interface %s: %v", *ifaceName, err)
}
// Attach the eBPF XDP program to the specified network interface
xdpLink, err := link.AttachXDP(link.XDPOptions{
Program: objs.CapturePacketData,
Interface: iface.Index,
})
if err != nil {
log.Fatalf("Error attaching XDP program: %v", err)
}
defer xdpLink.Close()
net.InterfaceByName: Retrieves the network interface by name. For example, if you specifyeth0, it will retrieve theeth0network interface.- Attaching XDP: The eBPF program is attached to the network interface using
link.AttachXDP. The program will now monitor packets on this interface at the XDP layer, which operates at the network device level.
Setting up the Ring Buffer for Data Collection #
// Create a ring buffer reader to receive events from the eBPF program
rd, err := ringbuf.NewReader(objs.PacketRingbuf)
if err != nil {
log.Fatalf("Error creating ring buffer reader: %v", err)
}
defer rd.Close()
log.Printf("Monitoring packets on interface: %s", *ifaceName)
ringbuf.NewReader: This function creates a reader for the ring buffer, which the eBPF program uses to send packet data to user space. This reader continuously reads new events (packet data) from the eBPF ring buffer.- The program then logs a message indicating that it is now monitoring packets on the specified interface.
Handling Graceful Exit #
// Set up signal handling for graceful exit
stopChan := make(chan os.Signal, 1)
signal.Notify(stopChan, os.Interrupt, syscall.SIGTERM)
- Signal Handling: This part sets up a signal listener for interrupts (such as
Ctrl+C). If the program receives an interrupt or termination signal, it can exit gracefully by cleaning up resources.
Main Packet Monitoring Loop #
for {
select {
case <-stopChan:
log.Println("Received interrupt, exiting...")
return
default:
// Read packet data from the ring buffer
record, err := rd.Read()
if err != nil {
log.Fatalf("Error reading from ring buffer: %v", err)
}
// Parse the raw packet data
var pkt packetData
err = binary.Read(bytes.NewReader(record.RawSample), binary.LittleEndian, &pkt)
if err != nil {
log.Fatalf("Error parsing packet data: %v", err)
}
- Main Loop: This is the main loop where the program continuously reads new packet data from the ring buffer.
rd.Read(): Reads a new record (captured packet) from the ring buffer.- Parsing Packet Data: The raw data from the ring buffer is parsed into a packetData struct using
binary.Read, interpreting the data in little-endian format.
Printing Packet Information #
// Convert IP addresses to human-readable format and print details
srcIP := intToIP(pkt.SrcIP)
dstIP := intToIP(pkt.DstIP)
protocolName := "Unknown"
if name, exists := protocolMap[int(pkt.Protocol)]; exists {
protocolName = name
}
fmt.Printf("Protocol: %s, Src: %s:%d, Dst: %s:%d, Size: %d bytes\n",
protocolName, srcIP, pkt.SrcPort, dstIP, pkt.DstPort, pkt.PacketSize)
}
}
}
- IP Conversion: The source and destination IPs, which are stored as
uint32values, are converted to human-readable IP addresses using the helper functionintToIP. -Protocol Lookup: The protocol number is mapped to a protocol name (like TCP or UDP) usingprotocolMap. If the protocol is not recognized, it defaults to “Unknown.” - Print Packet Details: The program prints the protocol, source IP and port, destination IP and port, and packet size in a readable format.
Helper Function: intToIP #
func intToIP(ip uint32) string {
ipBytes := make([]byte, 4)
binary.BigEndian.PutUint32(ipBytes, ip)
return net.IP(ipBytes).String()
}
intToIPconverts a 32-bit integer (IPv4 address) into a string format (x.x.x.x). It converts the integer to a byte slice usingbinary.BigEndian, which is necessary because IP addresses are typically stored in big-endian format.
Full code #
Click here to see the full code:
// main.go
package main
//go:generate go run github.com/cilium/ebpf/cmd/bpf2go packetSniff packet_sniff.c
import (
"bytes"
"encoding/binary"
"flag"
"fmt"
"log"
"net"
"os"
"os/signal"
"syscall"
"github.com/cilium/ebpf/link"
"github.com/cilium/ebpf/ringbuf"
"github.com/cilium/ebpf/rlimit"
)
var (
// Map protocol number to a human-readable protocol name
protocolMap = map[int]string{
1: "ICMP",
2: "IGMP",
6: "TCP",
17: "UDP",
41: "IPv6",
89: "OSPF",
132: "SCTP",
255: "Reserved",
}
)
// Struct that mirrors the packet_data structure in the eBPF program
type packetData struct {
SrcIP uint32
DstIP uint32
SrcPort uint16
DstPort uint16
Protocol uint32
PacketSize uint32
}
func main() {
// Parse the network interface name from the command line
ifaceName := flag.String("iface", "lo", "Network interface to monitor")
flag.Parse()
// Remove memory lock limit for eBPF
if err := rlimit.RemoveMemlock(); err != nil {
log.Fatalf("Failed to remove memlock: %v", err)
}
// Load compiled eBPF objects from ELF
var objs packetSniffObjects
if err := loadPacketSniffObjects(&objs, nil); err != nil {
log.Fatalf("Error loading eBPF objects: %v", err)
}
defer objs.Close()
// Get network interface by name
iface, err := net.InterfaceByName(*ifaceName)
if err != nil {
log.Fatalf("Error getting interface %s: %v", *ifaceName, err)
}
// Attach the eBPF XDP program to the specified network interface
xdpLink, err := link.AttachXDP(link.XDPOptions{
Program: objs.CapturePacketData,
Interface: iface.Index,
})
if err != nil {
log.Fatalf("Error attaching XDP program: %v", err)
}
defer xdpLink.Close()
// Create a ring buffer reader to receive events from the eBPF program
rd, err := ringbuf.NewReader(objs.PacketRingbuf)
if err != nil {
log.Fatalf("Error creating ring buffer reader: %v", err)
}
defer rd.Close()
log.Printf("Monitoring packets on interface: %s", *ifaceName)
// Set up signal handling for graceful exit
stopChan := make(chan os.Signal, 1)
signal.Notify(stopChan, os.Interrupt, syscall.SIGTERM)
// Main event loop
for {
select {
case <-stopChan:
log.Println("Received interrupt, exiting...")
return
default:
// Read packet data from the ring buffer
record, err := rd.Read()
if err != nil {
log.Fatalf("Error reading from ring buffer: %v", err)
}
// Parse the raw packet data
var pkt packetData
err = binary.Read(bytes.NewReader(record.RawSample), binary.LittleEndian, &pkt)
if err != nil {
log.Fatalf("Error parsing packet data: %v", err)
}
// Convert IP addresses to human-readable format and print details
srcIP := intToIP(pkt.SrcIP)
dstIP := intToIP(pkt.DstIP)
protocolName := "Unknown"
if name, exists := protocolMap[int(pkt.Protocol)]; exists {
protocolName = name
}
fmt.Printf("Protocol: %s, Src: %s:%d, Dst: %s:%d, Size: %d bytes\n",
protocolName, srcIP, pkt.SrcPort, dstIP, pkt.DstPort, pkt.PacketSize)
}
}
}
// Convert a uint32 IP address to a readable string
func intToIP(ip uint32) string {
ipBytes := make([]byte, 4)
binary.BigEndian.PutUint32(ipBytes, ip)
return net.IP(ipBytes).String()
}
Generate, Build and Run #
Now we can generate eBPF code and build the application.

Launching the application.
Where else can eBPF be used? #
eBPF’s flexibility makes it ideal for various real-world applications across security, observability, and more. Some key use cases include:
- Security Enforcement
eBPF can create advanced security mechanisms such as intrusion detection and runtime protection. It can monitor and block suspicious behavior (e.g., unauthorized file access), detect DDoS attacks, and secure container environments by monitoring system calls. Large companies like Netflix use eBPF to block malicious traffic during DDoS attacks in real time, filtering out harmful traffic at the network level with minimal performance cost. - Tracing and Debugging
eBPF supports dynamic tracing and debugging tools likebccandBPFtrace, enabling real-time performance analysis (e.g., memory use, CPU time) without needing to modify application code. - Load Balancers
eBPF helps build efficient load balancers directly in the Linux kernel, distributing network traffic across servers, reducing latency, and improving response times with minimal resource impact. - Observability and Metrics Collection
Tools like Prometheus and Grafana use eBPF to gather system metrics, track container behavior, and provide rich observability of system performance without slowing it down.